
nodeJS 专栏
1.什么是nodeJS?
- nodeJS是一个开源的,跨平台的JavaScript运行时环境。通俗的将,nodeJS就是一款应用程序,是一款软件,它可以让JavaScript运行在服务端。
- nodeJS作用: 开发服务器应用 、开发工具类应用 、开发桌面端应用
2.nodeJS的安装
1.应用程序安装
2.手动配置安装
3.nvm进行安装(管理多个版本) 推荐
- 1.下载地址:官方网站, 百度云资源 提取码: 363q (nvm-setup.exe)
- 2.注意:安装之前先卸载(删除)现有的node!!!
- 3.按照步骤安装即可,安装过程中需要切换安装路径,选择要安装的位置即可,一个是nvm的安装位置,一个是node的安装位置
- 3.安装完成后,在命令行输入nvm -v,如果出现版本号,则说明安装成功。
- 4.配置镜像地址
- 1.在命令行中输入nvm node_mirror https://npm.taobao.org/mirrors/node
- 2.在命令行中输入nvm npm_mirror https://npm.taobao.org/mirrors/
- 4.使用nvm命令
- 1.nvm list 查看已安装的node版本
- 2.nvm install 版本号 安装指定版本的node
- 3.nvm use 版本号 切换到指定版本的node
- 4.nvm uninstall 版本号 卸载指定版本的node
- 5.nvm ls-remote 查看远程服务器上可用的版本
- 6.nvm version 查看当前的版本
- 7.nvm root 查看当前的安装路径
- 8.nvm version-node 查看当前的node版本
- 9.nvm version-npm 查看当前的npm版本
- 10.nvm version-arch 查看当前的系统架构
- 11.nvm version-lts 查看当前的lts版本
- 12.nvm version-latest 查看当前的最新版本
- 13.nvm install-latest-npm 安装最新版本的npm
- 14.nvm reinstall-packages 重新安装全局包
- 15.nvm uninstall-packages 卸载全局包
- 16.nvm on 启用node.js版本管理
- 17.nvm off 禁用node.js版本管理
- 18.nvm proxy 查看当前的代理设置
- 19.nvm node_mirror [url] 设置或者查看node镜像地址
- 20.nvm npm_mirror [url] 设置或者查看npm镜像地址
3.nrm管理镜像地址
- 1.nrm是什么
- nrm是npm的镜像源管理工具,有时候国外资源太慢,使用这个就可以快速地在 npm 源间切换
- 2.安装
- 1.npm install -g nrm
- 3.使用
- 1.nrm ls 查看可选的镜像源地址
- 2.nrm use 镜像源名称 切换指定的镜像源
- 3.nrm test 查看当前镜像源的响应时间
- 4.nrm home 查看指定镜像源的地址
- 5.nrm add 镜像源名称 镜像源地址 添加新的镜像源
- 6.nrm del 镜像源名称 删除指定的镜像源
- 7.nrm current 查看当前的镜像源
- 8.nrm help 查看帮助
- 9.nrm version 查看nrm版本
3.命令行工具
1.CMD常用命令
- 1.cd 目录名 进入指定目录
- 2.cd .. 返回上一级目录
- 3.cd ../.. 返回上两级目录
- 4.dir 查看当前目录下的所有文件
- 5.dir /s 列出当前目录下的所有文件和子目录,包括隐藏文件
- 5.cls 清屏
- 6.md 目录名 创建一个文件夹
- 7.rd 目录名 删除一个文件夹
- 8.del 文件名 删除一个文件
- 9.echo 内容 输出内容
2.运行node.js文件
- 1.命令行工具切换到文件的所在目录,然后执行: node test.js
- 2.自动补全功能:输入文件的部分名称然后按tab键自动补全
4.模块API
1.注意事项:
- 1.nodeJs是不能使用浏览器API,例如DOM和BOM等,只能使用nodeJs内置的API
- 2.可以使用setTimeout()和setInterval()方法
- 3.nodeJs中没有window对象,但是可以使用顶级对象 global | globalThis访问顶级对象
- 4.nodeJs中没有document对象,但是可以使用process对象
- 5.nodeJs中没有console对象,但是可以使用console.log()方法
- 6.nodeJs中没有alert()方法,但是可以使用process.stdout.write()方法
2.Buffer
1.Buffer概念:
- Buffer是nodeJs全局变量,俗称缓冲区,是一个类似于Array的对象,用于表示固定长度的字节序列, 换句话说,Buffer就是一段固定长度的内存空间,用于处理二进制数据。
2.特点:
- 1.Buffer的大小一旦确定就不能修改
- 2.Buffer性能较好,可以直接对计算机内存将进行操作
- 3.每个元素的大小为1字节(byte)
3.创建Buffer:
1.Buffer.alloc(size[, fill[, encoding]]):创建一个指定大小的Buffer实例, 所有的元素都为0,如果没有设置fill,则默认填充为0,每次使用内存空间都会清零内存
- js
const buf = Buffer.alloc(10); console.log(buf); // <Buffer 00 00 00 00 00 00 00 00 00 00> const buf1 = Buffer.alloc(10, 1); console.log(buf1); // <Buffer 01 01 01 01 01 01 01 01 01 01> const buf2 = Buffer.alloc(10, 1, 'utf-8'); console.log(buf2); // <Buffer 01 01 01 01 01 01 01 01 01 01> 2.Buffer.allocUnsafe(size):创建一个指定大小的Buffer实例, 但是Buffer实例的元素可能包含敏感数据,每次使用内存空间时不会清零内存,所以不安全
- js
const buf = Buffer.allocUnsafe(10); console.log(buf); // <Buffer 00 00 00 00 00 00 00 00 00 00> 3.Buffer.from(array):创建一个Buffer实例, 该实例包含传入的数组中的所有字节
- js
const buf = Buffer.from([1, 2, 3, 4, 5]); console.log(buf); // <Buffer 01 02 03 04 05> 4.ASII码对照表
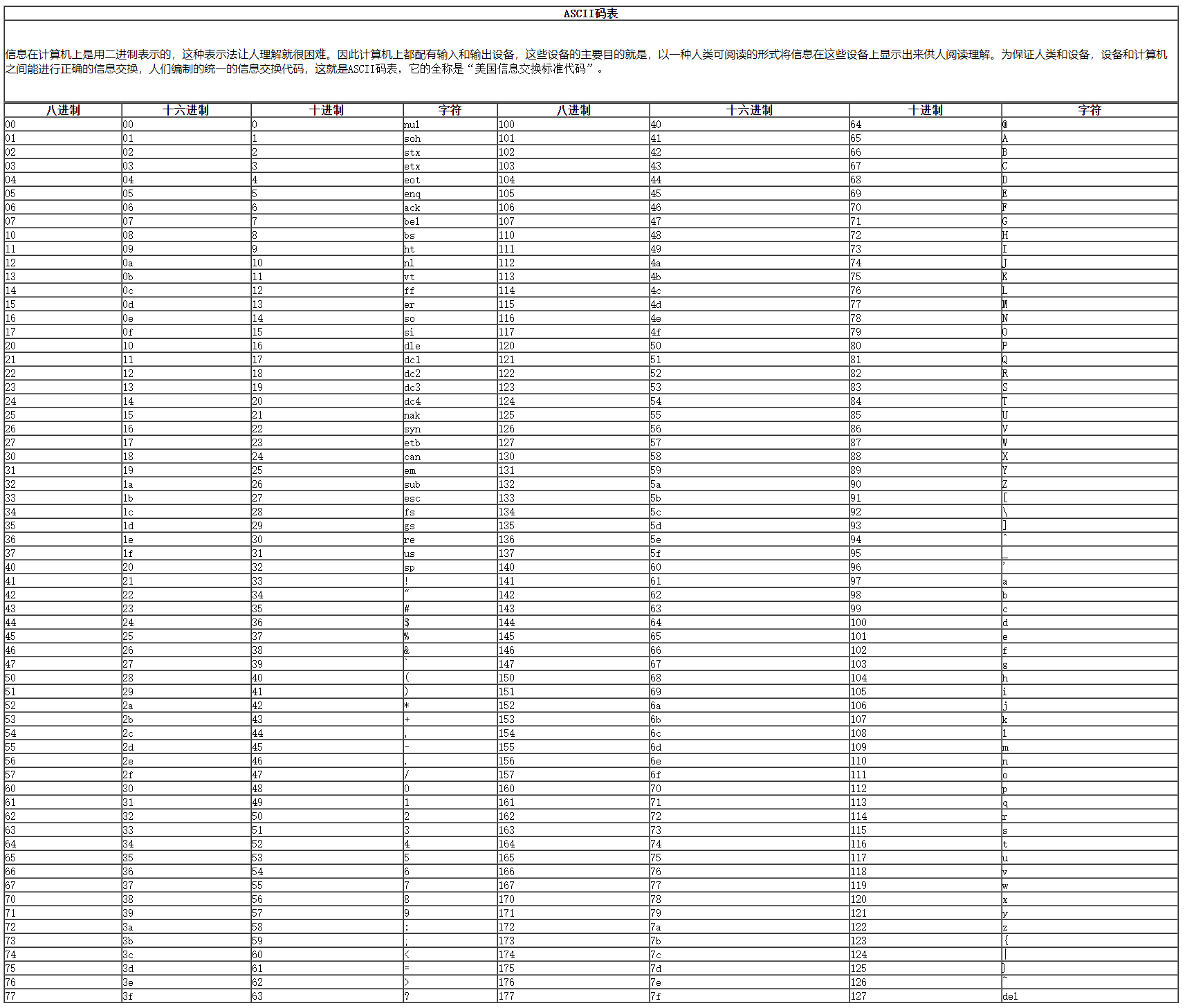
5.Buffer 与字符串的转换
1.Buffer 转换为字符串:
- 1.buf.toString([encoding[, start[, end]]])
- js
const buf = Buffer.from('hello'); console.log(buf.toString()); // hello console.log(buf.toString('utf-8')); // hello console.log(buf.toString('utf-8', 0, 3)); // hello - 2.buf.toJSON()
- js
const buf = Buffer.from('hello'); console.log(buf.toJSON()); // { type: 'Buffer', data: [ 104, 101, 108, 108, 111 ] }
2.字符串转换为Buffer:
- 1.Buffer.from(string[, encoding])
- js
const str = 'hello'; const buf = Buffer.from(str); console.log(buf); // <Buffer 68 65 6c 6c 6f>
3.Buffer 获取存储元素
- 1.buf[index]
- js
const buf = Buffer.from('hello'); console.log(buf[0].toString(2)); // 1100001
4.Buffer 修改存储元素
- 1.buf[index] = value
- js
const buf = Buffer.from('hello'); buf[0] = 100; console.log(buf.toString()); // elllo
5.Buffer 溢出
- 1.buf[index] = value
- js
const buf = Buffer.from('hello'); buf[0] = 361; // 舍弃高位的数字 0001 0110 1001 => 0110 1001 => 1001001 => 1001001 console.log(buf) // <Buffer 69 65 6c 6c 6f>
6.Buffer 中文
- 1.中文在UTF-8编码下占3个字节
- js
const buf = Buffer.from('你好'); console.log(buf); // <Buffer e4 bd a0 e5 a5 bd>
3.fs模块
- fs模块可以实现与硬盘的交互,例如:文件的创建、删除、重命名、移动、还有文件内容的读取、写入以及文件夹的相关操作。
- fs模块的使用:
1.writeFile异步写入文件
- js
// 执行同步代码,同步代码执行完在执行异步回调 // 1.导入fs模块 const fs = require('fs'); // 2.调用fs.writeFile(文件名, 内容[, 配置(可选)], 回调函数)方法,写入文件 fs.writeFile('./a.txt', 'hello world', function (err) { if (err) { console.log(err); return; } console.log('写入成功'); }); 2.writeFileSync同步写入文件
- js
// 写入操作执行完再向下执行其他代码 // 1.导入fs模块 const fs = require('fs'); // 2.调用fs.writeFileSync(文件名, 内容[, 配置(可选)])方法,写入文件 try { fs.writeFileSync('./a.txt', 'hello world'); console.log('写入成功'); } catch (err) { console.log(err); } 3.appendFile异步追加文件
- js
// 执行同步代码,同步代码执行完在执行异步回调 // 1.导入fs模块 const fs = require('fs'); // 2.调用fs.appendFile()方法,追加文件 fs.appendFile('./a.txt', 'hello world', function (err) { if (err) { console.log(err); return; } console.log('追加成功'); }); 4.appendFileSync同步追加文件
- js
// 追加操作执行完再向下执行其他代码 // 1.导入fs模块 const fs = require('fs'); // 2.调用fs.appendFileSync()方法,追加文件 try { fs.appendFileSync('./a.txt', 'hello world'); console.log('追加成功'); } catch (err) { console.log(err); } 5.writeFile、writeFileSync追加写入
- js
// 在配置项中添加 flag:'a' // 1.导入fs模块 const fs = require('fs'); // 2.调用fs.writeFileSync()方法,追加文件 try { fs.writeFileSync('./a.txt', 'hello world',{ flag:'a'}); // 追加写入 console.log('追加成功'); } catch (err) { console.log(err); } // 3.调用fs.writeFile()方法,追加文件 try { fs.writeFile('./a.txt', 'hello world',{ flag:'a'}, function (err) { if (err) { console.log(err); return; } console.log('追加成功'); }); } catch (err) { console.log(err); } 6.createWriteStream文件流式写入
- js
// 适用于写入频次较多的场景 // 1.导入fs模块 const fs = require('fs'); // 2.创建一个可写流 createWriteStream(文件路径, 配置项) const ws = fs.createWriteStream('./a.txt') // 3.通过可写流写入文件 ws.write('hello world\r\n'); ws.write('你好,世界\r\n'); // 4.关闭通道(可选,加不加都是可以的) ws.close(); 7.文件写入应用场景
- js
// 1.下载文件 // 2.安装软件 // 3.保存程序日志,如:git // 4.编辑器保存文件 // 5.视频录制 // 当需要持久化存储数据的时候,应该想到文件写入 8.readFile异步读取
- js
// fs.readFile(path[,options],callback)方法是异步读取文件 // 参数1:必选参数,字符串,表示文件的路径。 // 参数2:可选参数,表示以什么编码格式来读取文件。 // 参数3:可选参数,回调函数,用于接收文件的内容。 // 返回值:undefind // 1.导入fs模块 const fs = require('fs'); // 2.调用fs.readFile()方法,异步读取文件 fs.readFile('./a.txt', function (err, data) { if (err) { console.log(err); return; } // data 读取类型是 Buffer console.log(data.toString()); }); 9.readFileSync同步读取
- js
// fs.readFileSync(path[,options])方法是同步读取文件 // 参数1:必选参数,字符串,表示文件的路径。 // 参数2:可选参数,表示以什么编码格式来读取文件。 // 返回值:返回一个字符串,表示文件的内容。 // 1.导入fs模块 const fs = require('fs'); // 2.调用fs.readFileSync()方法,同步读取文件 const data = fs.readFileSync('./a.txt'); console.log(data.toString()); 10.createReadStream流式读取
- js
// fs.createReadStream(path[,options])方法是创建可读流 // 参数1:必选参数,字符串,表示文件的路径。 // 参数2:可选参数,表示以什么编码格式来读取文件。 // 返回值:返回一个可读流对象。 // 1.导入fs模块 const fs = require('fs'); // 2.创建可读流 const rs = fs.createReadStream('./a.txt', { flags: 'r', // 文件操作模式 encoding: 'utf-8', // 字符编码 autoClose: true, // 自动关闭文件 start: 0, // 文件读取的起始位置 end: 9 // 文件读取的结束位置 }); // 3.监听流的open事件 rs.on('open', function () { console.log('文件被打开'); }); // 4.监听流的close事件 rs.on('close', function () { console.log('文件被关闭'); }); // 5.读取文件内容 rs.on('data', function (chunk) { console.log(chunk); // 分块读取,类型 Buffer console.log(chunk.length) // 每块的大小 }); // 6.监听流的error事件 rs.on('error', function (err) { console.log(err); }); // 7.监听流的end事件(可选) rs.on('end', function () { console.log('文件读取完成'); }); 11.读取文件的应用场景
- js
// 1.电脑开机 // 2.程序运行 // 3.编辑器打开文件 // 4.查看图片 // 5.播放视频 // 6.播放音乐 // 7.git查看日志 // 8.上传文件 // 9.查看聊天记录 // 10. ...... 12.复制文件 (流的方式)
- js
// 1.创建可读流(配置项选填,可不写) const rs = fs.createReadStream('./1.txt', { encoding: 'utf-8', autoClose: true, start: 0, end: 9 }); // 2.创建可写流(配置项选填,可不写) const ws = fs.createWriteStream('./2.txt', { encoding: 'utf-8', autoClose: true }); // 3.监听流的open事件 rs.on('open', function () { console.log('文件被打开'); }); // 4.监听流的close事件 rs.on('close', function () { console.log('文件被关闭'); }); // 5.监听流的data事件 rs.on('data', function (data) { console.log(data); // 6.将读取到的内容写入到文件中 ws.write(data); }); // 7.监听流的error事件 rs.on('error', function (err) { console.log(err); }); // 8.监听流的end事件(可选) rs.on('end', function () { console.log('文件读取完成'); // 9.关闭文件 ws.end(); }); // 使用管道复制文件 rs.pipe(ws); 13.文件重命名和移动
- js
// 1.异步重命名文件 rename(旧文件名, 新文件名, 回调函数) // 导入fs模块 const fs = require('fs'); // 重命名文件 remove(旧文件名, 新文件名, 回调函数) fs.rename('./1.txt', './2.txt', function (err) { if (err) { console.log(err); return; } console.log('文件重命名成功'); }); // 移动文件 rename(旧文件名, 新文件名, 回调函数) fs.rename('./2.txt', './test/2.txt', function (err) { if (err) { console.log(err); return; } console.log('文件移动成功'); }); // 2.同步重命名文件 renameSync(旧文件名, 新文件名) fs.renameSync('./2.txt', './test/2.txt'); 14.删除文件
- js
// unlink方法删除 // 1.异步删除文件 unlink(文件路径, 回调函数) // 导入fs模块 const fs = require('fs'); // 删除文件 unlink(文件路径, 回调函数) fs.unlink('./test/2.txt', function (err) { if (err) { console.log(err); return; } console.log('文件删除成功'); }); // 2.同步删除文件 unlinkSync(文件路径) fs.unlinkSync('./test/2.txt'); // rm方法删除 // 1.异步删除文件 rm(文件路径, 回调函数) fs.rm('./test/2.txt', function (err) { if (err) { console.log(err); return; } console.log('文件删除成功'); }); // 2.同步删除文件 rmSync(文件路径) fs.rmSync('./test/2.txt'); 15.文件夹操作
- js
// 导入fs模块 const fs = require('fs'); // 创建文件夹 mkdir(文件夹路径, 回调函数) // 多目录创建只需要在路径中添加即可,例如:./test/a/b/c // 多目录创建需要添加配置参数:{recursive: true},不是多目录配置项可不加 fs.mkdir('./test',{recursive: true}, function (err) { if (err) { console.log(err); return; } console.log('文件夹创建成功'); }); // 删除文件夹 rmdir(文件夹路径, 回调函数)(不推荐使用,这个API可能将来会被移除,推荐使用rm方法) // 多目录删除只需要添加配置参数即可:{recursive: true},不是多目录配置项可不加 fs.rmdir('./test',{recursive: true }, function (err) { if (err) { console.log(err); return; } console.log('文件夹删除成功'); }); // rm(文件夹路径, 回调函数)(推荐使用) fs.rm('./test',{recursive: true }, function (err) { if (err) { console.log(err); return; } console.log('文件夹删除成功'); }); // 读取文件夹 readdir(文件夹路径, 回调函数) // 回调函数中的files是一个数组,包含文件夹中的所有文件名 fs.readdir('./test', function (err, files) { if (err) { console.log(err); return; } console.log(files); }); 16.查看资源状态
- js
// 导入fs模块 const fs = require('fs'); // stat(文件路径, 回调函数) fs.stat('./test.txt', function (err, stats) { if (err) { console.log(err); return; } console.log(stats); // 返回一个fs.Stats对象 console.log(stats.isFile()); // 判断是否是文件 console.log(stats.isDirectory()); // 判断是否是文件夹 }); 17.路径补充说明
- js
// 相对路径问题 // 相对路径:相对于当前文件所在的路径 // 例如:./test.txt 或者 test.txt 表示当前文件所在的文件夹下的test.txt文件 // 生成文件的路径-> 相对路径参照物:命令行的工作目录 // node .\test\test1.js 生成文件会在 test同级目录下 // 绝对路径:从根目录开始的路径 // 例如:C:\Users\test.txt 或者 /test.txt 表示C盘下的Users文件夹下的test.txt文件 // 绝对路径,‘全局变量’: __dirname 表示所在文件的所在目录的绝对路径
4.path模块
- path模块提供了操作路径的功能,例如:路径拼接、获取文件名、获取扩展名等。
- path模块的使用:
1.resolve()方法:用于拼接规范的绝对路径
- js
// 导入path模块 const path = require('path'); // resolve()方法用于拼接路径 const pathStr = path.resolve(__dirname,'./test.txt'); console.log(pathStr); // 输出:C:\Users\test.txt 2.join()方法:用于拼接路径
- js
// 导入path模块 const path = require('path'); // join()方法用于拼接路径 const pathStr = path.join('a', 'b', 'c', '../', './d', 'e'); console.log(pathStr); // 输出:a\b\d\e 3.sep()方法:用于获取操作系统的路径分隔符
- js
// 导入path模块 const path = require('path'); // sep()方法用于获取操作系统的路径分隔符 const sep = path.sep; console.log(sep); // 输出:\ 或者 /,取决于操作系统 window为\,linux为/ 4.parse()方法:用于将路径字符串解析成对象
- js
// 导入path模块 const path = require('path'); // parse()方法用于将路径字符串解析成对象 const pathObj = path.parse('a/b/c/d.txt'); console.log(pathObj); // 输出:{ root: '', dir: 'a/b/c', base: 'd.txt', ext: '.txt', name: 'd' } 5.basename()方法:用于获取路径的基础名称
- js
// 导入path模块 const path = require('path'); // basename()方法用于获取路径的基础名称 const basename = path.basename('a/b/c/d.txt');// 输出:d.txt console.log(basename); 6.dirname()方法:用于获取路径的目录名称
- js
// 导入path模块 const path = require('path'); // dirname()方法用于获取路径的目录名称 const dirname = path.dirname('a/b/c/d.txt');// 输出:a/b/c console.log(dirname); 7.extname()方法:用于获取路径的扩展名
- js
// 导入path模块 const path = require('path'); // extname()方法用于获取路径的扩展名 const extname = path.extname('a/b/c/d.txt');// 输出:.txt console.log(extname);
5.HTTP协议
1.什么是HTTP协议
- 超文本传输协议(HyperText Transfer Protocol,简称HTTP)是一种用于传输超文本的协议,它规定了客户端和服务器之间如何通信。
2.什么是超文本
- 超文本就是指页面中除了可以包含文本,还可以包含图片、音频、视频、链接等非文本元素。
3.什么是客户端
- 发送请求的一方,可以是浏览器、手机APP、其他服务器等。
4.什么是服务器
- 接收请求的一方,可以是Web服务器、数据库服务器、文件服务器等。
5.窥探HTTP报文:
- 安装插件:Fiddler,这里我就不在安装了,需要使用该软件,可以自行百度下载。
- 打开Fiddler,然后打开浏览器,访问http://www.baidu.com,然后查看Fiddler中的请求和响应。
6.请求报文结构
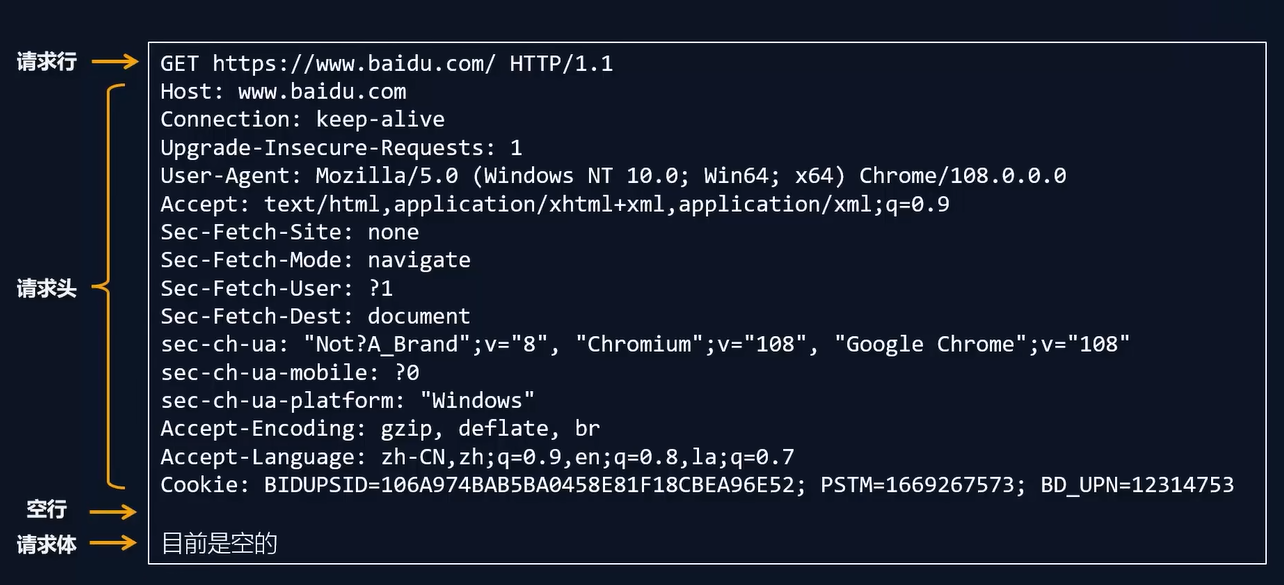
7.请求行

关于请求头更多的介绍,可以查看MDN
8.请求体
请求体是可选的,只有当请求方法是POST、PUT、PATCH等时,才会包含请求体。
请求体中可以包含用户提交的数据,例如表单数据、JSON数据等。
请求体的格式由Content-Type请求头指定,常见的格式有:application/x-www-form-urlencoded、multipart/form-data、application/json等。
请求体的数据可以通过req.body获取,例如:
- js
const http = require('http'); const server = http.createServer((req, res) => { if (req.method === 'POST') { let body = ''; req.on('data', chunk => { body += chunk.toString(); }); req.on('end', () => { console.log(body); res.end('ok'); }); } }); server.listen(3000); 9.响应报文结构
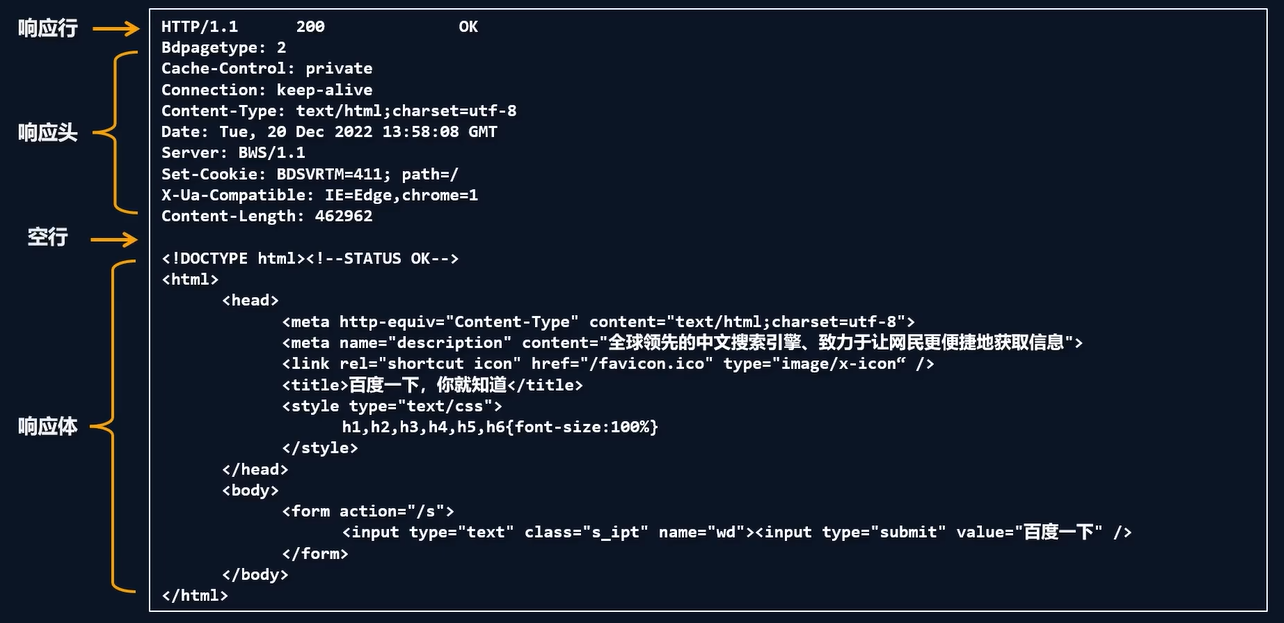
10.响应行

11.响应状态码
- js
/** * 1xx:表示请求已接收,继续处理。 * 2xx:表示请求成功。例如,200表示请求成功,201表示请求成功并创建了新的资源。 * 3xx:表示重定向。例如,301表示永久重定向,302表示临时重定向。 * 4xx:表示客户端错误。例如,400表示请求无效,401表示未授权,404表示资源未找到。 * 5xx:表示服务器错误。例如,500表示服务器内部错误,503表示服务器暂时无法处理请求。 **/
6.IP的分类
- js
/** * 本机回环IP地址:127.0.0.1 ~ 127.255.255.254,用于测试本机网络功能。 * 局域网IP地址:192.168.0.0 ~ 192.168.255.255,用于局域网内部通信。例如,192.168.1.1表示局域网内的一个IP地址。 * 公网IP地址:由ISP(互联网服务提供商)分配,用于互联网通信。例如,8.8.8.8表示Google的DNS服务器。 **/ 7.端口的分类
- js
/** * 应用程序的数字标识符,用于区分不同的应用程序。 * 一台现代计算机有65536个端口,从0到65535。例如,HTTP使用端口80,HTTPS使用端口443,FTP使用端口21。 * 一个应用程序可以使用一个或多个端口。 * 端口作用:实现不同主机应用程序之间的通信。例如,浏览器使用端口80与Web服务器通信,FTP客户端使用端口21与FTP服务器通信。 **/ 8.http模块
1.创建http服务器
- js
// 引入http模块 const http = require('http'); // 创建http服务器 // 回调函数:当有请求到达时,会自动执行该回调函数 const server = http.createServer((request,response)=> { console.log(request.headers) // 请求头 response.end('hello world'); // 设置响应体 }); // 监听端口,启动服务 server.listen(3000,()=>{ console.log('server is running on port 3000'); }); /** * 注意事项: * 1.启动服务器 * 控制台输入 node 创建的服务器文件.js // 访问http://localhost:3000 * 2.停止服务器 * 控制台输入 ctrl + c 或者 node 创建的服务器文件.js stop * 3.响应体中有中文时,需要设置响应头 * response.setHeader('Content-Type', 'text/html; charset=utf-8'); * 4.端口被占用 * 1.关闭占用端口的进程 * 2.修改端口号 * 5.http协议默认端口是80。HTTP服务开发常用端口有:8090、8080、9000、3000等,HTTPS协议的默认端口是:443。 * 如果端口被其他程序占用,可以使用资源监视器找到占用端口的程序,然后使用任务管理器关闭对应的程序 **/
2.获取HTTP请求报文
- js
/** * 想要获取请求数据,需要通过request对象来获取 * request对象包含了客户端发送过来的所有信息,例如请求路径、请求头、请求体等 * request对象是一个可读流,可以通过on('data',callback)来获取请求体数据,通过on('end',callback)来监听请求体数据传输完成 * request.method:获取请求方法 * request.url:获取请求路径 * request.headers:获取请求头 * request.on('data',callback):获取请求体数据 * request.on('end',callback):监听请求体数据传输完成 * request.httpVersion:获取HTTP版本 * request.socket.remoteAddress:获取客户端IP地址 * request.socket.remotePort:获取客户端端口号 * request.socket.localAddress:获取服务器IP地址 * request.socket.localPort:获取服务器端口号 * require('url').parse(request.url,true):解析请求路径,第二个参数为true时,将查询字符串解析为对象 * require('querystring').parse(require('url').parse(request.url,true).query):将查询字符串解析为对象 * 注意事项 * 1.request.url 只能获取路径以及查询字符串,无法获取 URL 中的域名以及协议的内容 * 2.request.headers 将请求信息转化成一个对象,并将属性名全部转化为小写,例如:Host -> host * 3.关于路径:如果访问网站的时候,只填写了域名,没有填写路径,那么默认访问网站的根路径,根路径就是网站的首页 * 4.关于favicon: 这个请求是属于浏览器自动发送的请求 **/ 3.获取HTTP请求体数据
- js
const http = require('http'); const server = http.createServer((request,response)=>{ // console.log(request.headers) // 创建一个变量用于接收传递的buffer数据 let body = '' request.on('data',(chunk)=>{ // 每个chunk是一个buffer console.log(chunk) // 将buffer数据拼接 body += chunk }) request.on('end',()=>{ // 获取请求体数据 console.log(body) response.end('Hello World') }) }) server.listen(9000,()=>{ console.log('Server is running on port 9000'); }) 4.获取HTTP请求路径与查询字符串
- js
// 方式一 const http = require('http'); // 导入url模块用于将请求路径解析为对象 const url = require('url'); const server = http.createServer((request,response)=>{ request.on('end',()=>{ // 获取请求路径与查询字符串的解析对象,设置true 则将查询字符串解析为对象 let res = url.parse(request.url,true) // 获取请求路径 console.log(res.pathname) // 获取查询参数 console.log(res.query.xxx) response.end('Hello World') }) }) server.listen(9000,()=>{ console.log('Server is running on port 9000'); }) - js
// 方式二 const http = require('http'); const server = http.createServer((request,response)=>{ // 实例化URL对象 let url = new URL(request.url,`http://${request.headers.host}`) // 获取查询参数 console.log(url.searchParams.get('xxx')) response.end('Hello World') }) server.listen(9000,()=>{ console.log('Server is running on port 9000'); }) 5.设置HTTP响应报文
- js
/** * 设置响应状态码 response.statusCode = 200 * 设置响应状态描述 response.statusMessage = 'OK' * 设置响应头信息 response.setHeader('头名','头值') * 设置多个同名响应头信息 response.setHeader('头名',['头值1','头值2']) * 设置响应体信息 response.write('响应体内容') response.end('响应体内容') (如果wirte设置响应体 end一般不在设置响应体) **/ // write 和 end 的两种使用情况 // 1.write 和 end 的结合使用 响应体相对分散 response.write('hello') response.write('world') // 每一个请求,在处理的时候必须要执行 end 方法,否则请求无法结束,客户端无法获取到响应结果(有且只有一个end方法) response.end() // 2. 单独使用end 方法 响应体相对集中 // end 参数可以是字符串也可以是一个buffer // let html = fs.writeFileSync('./index.html') response.end('hello world') // response.end(html) 6.网页资源加载基本过程
- js
// 1.浏览器向服务器发送请求 // 2.服务器接收到请求后,根据请求路径,查找对应的资源文件 // 3.服务器将资源文件的内容,作为响应体,返回给浏览器 // 4.浏览器接收到响应结果后,根据响应结果,解析响应体内容,并渲染到页面中 // 5.解析响应体过程中如果发现由外部资源链接,浏览器会再次向服务器发送请求获取外部资源, // 整个解析过程中请求是并发的,不是等到上个请求结束才发送请求获取下个资源 7.静态资源和动态资源
- js
/** * 静态资源:浏览器直接请求服务器上的文件,服务器直接返回文件内容给浏览器 * 动态资源:服务器接收到请求后,根据请求路径,查找对应的资源文件,然后对资源文件进行解析,将解析结果作为响应体返回给浏览器 * 静态资源:html、css、js、图片、视频、音频 * 动态资源:.php、.jsp、.asp、.aspx、.do、.action、.py、.rb、.lua、.pl、.cgi、.shtml、.htaccess... **/ 8.静态资源服务的搭建
- js
// 导入http模块 const http = require('http') // 导入fs模块 const fs = require('fs') // 创建服务器 const server = http.createServer((request, response) => { // 1.获取请求路径 let {pathname} = new URL(request.url, 'http://127.0.0.1') // 2.根据请求路径,查找对应的资源文件 let filePath = __dirname+'/静态资源存放的目录' + pathname // 3.读取资源文件的内容,将内容作为响应体返回给浏览器 fs.readFile(filePath, (err, data) => { if (err) { // 读取文件失败 response.statusCode=404; response.writeHead(404, { 'Content-Type': 'text/html;charset=utf-8' }) response.end('404 Not Found') } else { // 读取文件成功 response.writeHead(200, { 'Content-Type': 'text/html;charset=utf-8' }) response.end(data) } }) }) // 监听端口 server.listen(9000, () => { console.log('服务器已启动,端口号为9000') }) 9.静态资源目录或网站根目录
- js
// HTTP服务在哪个文件夹中寻找静态资源,那个文件夹就是静态资源目录,也称之为网站根目录 // 获取网站根目录 __dirname + '/静态资源存放目录' const root = __dirname + '/page' 10.网页中的URL
- js
/** * 网页中的URL主要分为两大类:相对路径与绝对路径 * * 绝对路径(可靠) * 绝对路径可靠性强,而且相对容易理解,在项目中运用较多 * 形式: 特点: * http://www.xxx.com/xxx 直接向目标资源发送请求,容易理解。网站的外链会用到此形式(完整路径) * //www.xxx.com/xxx 与页面URL的协议拼接形成完整URL再发送请求。大型网站用的较多(省略协议) * /xxx 与页面URL的协议、域名、端口拼接形成完整URL再发送请求,中小型网站(省略协议域名端口) * * 相对路径(不可靠) * 相对路径在发送请求时,需要与当前页面URL路径进行计算,得到完整的URL后,再发送请求,学习阶段用的较多 * 形式: 最终URL: * ./xxx/xxx1.css http://localhost:9000/xxx/xxx1.css * xxx/xxx2.html http://localhost:9000/xxx/xxx2.html * ../xxx/xxx3.js http://localhost:9000/xxx/xxx3.js * ../../xxx/xxx4.mp4 http://localhost:9000/xxx/xxx4.mp4 * * 网页中使用URL的场景 * 包括但不限于以下场景 * a标签的href属性 * img标签的src属性 * video、audio标签的src属性 * script标签的src属性 * link标签的href属性 * form标签的action属性 * iframe标签的src属性 * AJAX请求的URL * ... **/ 11.设置MIME类型
- js
/** * MIME类型(媒体类型) * MIME类型全称为:Multipurpose Internet Mail Extensions,即多用途互联网邮件扩展类型 * MIME类型是一种标准,用来表示文档、文件或字节流的性质和格式,使得同一个文件能够被多个应用程序处理 * MIME类型通常由两部分组成:主类型/子类型,中间由斜杠分隔 * mime 类型结构:[type]/[sub-type] * 例如:text/html text/css image/jpeg application/json * HTTP服务可以设置响应头 Content-Type 来表明响应体的MIME类型,浏览器会根据该类型决定如何处理资源 * 下面是常见文件对应的mime类型 * 文件类型 MIME类型 * HTML文档 text/html * CSS样式表 text/css * JavaScript脚本 application/javascript * 图片文件 image/jpeg image/png image/gif * JSON数据 application/json * PDF文件 application/pdf * Word文档 application/msword * Excel文件 application/vnd.ms-excel * PPT文件 application/vnd.ms-powerpoint * 文本文件 text/plain * 压缩文件 application/zip application/gzip * 视频文件 video/mp4 video/ogg * 音频文件 audio/mpeg audio/ogg * 对于未知的资源类型,可以选择application/octet-stream,表示二进制数据,浏览器会下载该文件 **/ // 设置mime类型 // 导入path模块 const path = require('path'); // 导入http模块 const http = require('http'); // 导入fs模块 const fs = require('fs'); const mime = require('mime'); // 创建web服务器实例 const server = http.createServer((request, response) => { // 判断请求方式是否正确 if (request.method !== 'GET') { response.statusCode = 405; response.end('Method Not Allowed'); return; } let {pathname} = new URL(request.url, 'http://127.0.0.1'); // 获取根路径 let root = path.join(__dirname, 'public'); // 获取文件路径 let filePath = path.join(root, pathname); // 获取文件后缀名 const extname = path.extname(filePath).slice(1); const type = mime.getType(extname) // 获取文件类型 console.log(extname); console.log(mime); fs.readFile('./index.html', (err, data) => { if (err) { // 错误状态处理 switch (err.code) { case 'ENOENT': // 文件不存在 response.statusCode = 404; response.end('404 Not Found'); break; case 'EPERM': // 权限不足 response.statusCode = 403; response.end('403 FORBIDDEN'); break; case 'EACCES': // 没有权限 response.statusCode = 403; response.end('Forbidden'); break; default: // 服务器的内部错误 response.statusCode = 500; response.end('Internal Server Error'); break; } } }); if(type){ // text/html;charset=utf-8 解决返回中文乱码问题 // 这里设置 utf-8 编码,解决中文乱码问题的优先级高于html header中的meta标签设置的utf-8 // css js 在解析时默认使用浏览器解析字符集 utf-8 所以不用设置字符集 response.setHeader('Content-Type', type + ';charset=utf-8'); }else{ response.setHeader('Content-Type', 'application/octet-stream'); } }); // 不手动设置mime类型,浏览器会根据文件后缀名来自动设置mime类型 12.GET 和 POST 请求
- js
/** * 使用场景: * GET请求的情况 * 在地址栏中直接输入url访问 * 点击a链接访问 * link标签引入css文件 * script标签引入js文件 * video audio标签引入媒体文件 * img标签引入图片文件 * form表单设置method为get提交(默认就是get请求,不区分大小写) * ajax请求设置type为get * POST请求的情况 * form表单设置method为post提交(不区分大小写) * ajax请求设置type为post * GET 和 POST 请求的区别 * GET 和 POST 是http协议中两种请求方式,主要区别在于: * 1.作用:GET主要用来获取数据, POST主要用来提交数据(一般情况下,但不是绝对的,get请求也可以提交数据,post请求也可以获取数据) * 2.参数位置:GET请求的参数放在url中,POST请求的参数放在请求体中(一般情况下,但不是绝对的get请求也可以放在请求体中,post请求也可以放在url中) * 3.安全性:POST请求相对GET安全些,因为在浏览器中参数会暴露在地址栏 * 4.报文体积:GET请求的大小有限制,一般为2k,POST请求大小没有限制 **/ 5.模块化
1. 模块化概念
- js
/** * 模块化与模块: * 模块化是指将一个复杂的程序文件依据一定规则(规范)拆分成多个文件的过程称之为模块化。 * 其中拆分出的每个文件就是一个模块,模块的内部数据是私有的,不过模块可以暴露内部数据以便其他模块使用 * 模块化项目: * 编码时是按照模块一个一个编码的,整个项目就是一个模块化的项目。 * 模块化优点: * 模块化可以提高代码的可维护性、可读性和可复用性。 * 模块化有多种实现方式,如CommonJS、AMD、CMD、ES6模块等。 * CommonJS是Node.js的模块化规范,使用require和module.exports来导入和导出模块。 * AMD和CMD是浏览器端的模块化规范,使用define和require来导入和导出模块。 * ES6模块是JavaScript的模块化规范,使用import和export来导入和导出模块。 **/ 2. CommonJS模块化
- js
/** * CommonJS模块化: * CommonJS是Node.js的模块化规范,使用require和module.exports来导入和导出模块。 * require:用于导入模块,返回模块的导出对象。 * module.exports:用于导出模块,将模块的导出对象赋值给module.exports。 * module.exports和exports的区别: * module.exports是 CommonJS模块的导出对象(任意数据),而exports是module.exports的一个引用 exports = module.exports = {} 。 * 在模块中,module.exports和exports指向同一个对象,但module.exports可以重新赋值,而exports不能 * module.exports = '123' 可以, exports = '123' 无效。 * 如果module.exports和exports同时存在,以module.exports为准。 * CommonJS模块化示例: * 使用module.exports * module.exports = { * name: '张三', * age: 18, * sayHello: function() { * console.log('Hello, my name is ' + this.name + ', I am ' + this.age + ' years old.'); * } * }; * const person = require('./person'); * person.sayHello(); * * 使用exports * exports.name = '张三'; * exports.age = 18; * exports.sayHello = function() { * console.log('Hello, my name is ' + this.name + ', I am ' + this.age + ' years old.'); * }; * const person = require('./person'); * person.sayHello(); * **/ 3.导入模块
- js
/** * 导入模块 * 在模块中使用require传入文件路径即可引入文件 * const test = require('./person.js'); * reuqire使用的一些注意事项: * 1. 对于自己创建的模块,导入时路径建议写相对路径,且不能省略./和../。 * 2. js 和 json 文件导入时可以不写后缀,c/c++编写的node扩展文件也可以不写后缀,但是一般用不到 * 3. 如果导入其他类型的文件,会以js文件处理,如果导入的文件没有后缀,会依次尝试添加.js、.json、.node后缀,如果尝试了所有后缀都没有,会报错 * 4. 如果导入的路径是个文件夹(在包管理工具中用到),则会首先检测该文件夹下package.json文件中main属性对应的文件, * 如果main属性不存在,或者package.json文件不存在,则默认会查找该文件夹下的index.js文件和index.json文件, * (js文件优先级高于json文件,同名时优先查找js文件)如果以上文件都不存在,则报错 * 5. 导入node.js内置模块时,直接require模块的名字即可,无需加./和../。 * 6. modules.exports 、exports 以及require 这些都是 CommonJS模块化规范中的内容。 * 而node.js实现了CommonJS模块化规范,两者的关系有点像JavaScript和ECMAScript的关系。 * **/ /** * 导入模块基本流程 * 自定义模块的基本流程: * 1.将相对路径转换为绝对路径,定位目标文件。 * 2.缓存检测。 * 3.读取目标文件代码。 * 4.将目标文件代码封装为一个函数并执行(自执行函数)。通过 arguments.callee.toString() 可以查看函数体。 * 5.缓存模块的值。 * 6.返回module.exports的值。 **/ 6.包管理工具
1.包管理工具的介绍
- js
/** * 包管理工具的介绍 * 1.包(package)是多个模块的集合,Node.js的包类似于JavaScript的库或框架,如jQuery、Vue.js等。 * 2.包的规范: * 1.包必须以文件夹的形式存在,文件夹名称就是包名称。 * 2.包的文件夹中必须包含 package.json 文件,package.json 文件中必须包含 name、version、main 三个属性。 * name 是包的名称,version 是包的版本,main 是包的入口文件。 * 3.包的文件夹中可以包含 README.md、LICENSE、bin 等文件。 **/ /** * 常用的包管理工具 * 1. npm(Node Package Manager)是 Node.js 的包管理工具,用于管理 Node.js 的包。 * npm 的官方网站是 https://www.npmjs.com/。 * npm 的官方文档是 https://docs.npmjs.com/。 * 2. yarn 是 Facebook 开发的包管理工具,用于管理 Node.js 的包。 * yarn 的官方网站是 https://yarnpkg.com/。 * yarn 的官方文档是 https://yarnpkg.com/en/docs/。 * 3. pnpm 是一个高效的包管理工具,用于管理 Node.js 的包。 * pnpm 的官方网站是 https://pnpm.io/。 * pnpm 的官方文档是 https://pnpm.io/en/docs/。 **/ 2.npm 的使用
- js
/** * 1. npm 的安装 * npm 是 Node.js 的包管理工具,因此安装 npm 的前提是已经安装了 Node.js。 * 在 Node.js 的安装过程中,npm 也会被自动安装。 * 可以通过以下命令来检查 npm 是否已经安装: * npm -v * 如果 npm 已经安装,则会显示 npm 的版本号。 **/ /** * 2. npm 的使用 * npm 的使用非常简单,只需要在命令行中输入 npm 命令即可。 * npm 的常用命令如下: * npm install:安装包。 * npm uninstall:卸载包。 * npm update:更新包。 * npm list:列出已安装的包。 * npm run:运行脚本。 * 例如,要安装一个包,可以使用以下命令: * npm install express * 这将会安装 express 包,并将其添加到项目的 package.json 文件的 dependencies 中。 * 如果要卸载一个包,可以使用以下命令: * npm uninstall express * 这将会卸载 express 包,并将其从项目的 package.json 文件的 dependencies 中移除。 * 如果要更新一个包,可以使用以下命令: * npm update express * 这将会更新 express 包到最新版本。 * 如果要列出已安装的包,可以使用以下命令: * npm list * 这将会列出项目中已安装的所有包。 * 如果要运行脚本,可以使用以下命令: * npm run <script-name> * 这将会运行项目中的脚本。 * 执行安装后会生成两个文件 一个是nodeModules文件夹 一个是package-lock.json文件 * nodeModules文件夹存放的是安装的包 * package-lock.js 锁定包的版本 * 所安装的包,我们称之为依赖包也简称依赖, **/ /** * 初始化项目 * npm init 命令用于初始化项目,生成 package.json 文件。 * 在命令行中输入 npm init,然后按照提示输入相关信息,即可生成 package.json 文件。 * 如果不想手动输入信息,可以使用以下命令: * npm init -y * 这将会使用默认值生成 package.json 文件。 * package.json 文件中包含了项目的名称、版本、描述、作者、许可证等信息,以及项目的依赖包。 * 例如,以下是一个 package.json 文件的示例: * { * "name": "my-app", * "version": "1.0.0", * "description": "My first Node.js app", * "main": "index.js", * "scripts": { * "start": "node index.js" * }, * "author": "John Doe", * "license": "MIT", * "dependencies": { * "express": "^4.17.1" * } * } * 在这个示例中, * 项目的名称是 my-app, * 版本是 1.0.0, * 描述是 My first Node.js app, * 主文件是 index.js, * 脚本是 start, * 作者是 John Doe, * 许可证是 MIT, * 依赖包是 express。 * package.json 文件中的 dependencies 字段列出了项目的依赖包,这些包会在安装项目时自动安装。 * 注意: * 1. package name(包名)不能使用中文、大写,默认值是文件夹的名称,所以文件夹的名称也不能使用中文和大写。 * 2. version(版本号)遵循语义化版本规范,格式为 x.y.z,其中 x 是主版本号,y 是次版本号,z 是修订号 ,必须位数字,默认是1.0.0。 * 3. ISC证书与MIT证书功能上是相同的,关于开源证书扩展阅读 * https://www.ruanyifeng.com/blog/2011/05/how_to_choose_free_software_licenses.html * 4. package.json 可以手动创建与修改 * 5. 使用npm init -y 或者 npm init --yes 可以快速创建package.json文件 **/ 3. npm 搜索包
- js
/** * 两种搜索方式 * 1. 命令行中搜索: npm search 包名 或者 npm s 包名 * 2. 在npm官网搜索: https://www.npmjs.com/ 4. require 导入npm包的基本流程
- js
/** * 1. 在node_modules文件夹中查找包 * 2. 如果找到包,则根据包的package.json中的main字段指定的文件作为包的入口文件 * 3. 如果没有找到包,则去上级目录的node_modules文件夹中查找 * 4. 如果没有找到包,则继续向上级目录查找,直到盘根目录 * 5. 如果没有找到包,则报错 **/ 5. 生产依赖与开发依赖
- js
/** * 生产环境 与 开发环境 * 生产环境:项目上线之后,也就是用户访问项目的时候,就是生产环境 * 开发环境:项目开发阶段,也就是程序员编写代码的时候,就是开发环境 * * 生产依赖 与 开发依赖 * 生产依赖:项目上线之后,依然需要使用的包,就是生产依赖 * 开发依赖:项目上线之后,不需要使用的包,就是开发依赖 * 我们可以在安装时设置选项来区分依赖的类型,目前分为两类: * 类型 安装命令 补充 * 生产依赖 npm i -S 包名 -S 等效与 --save , -S是默认选项 npm i --save 包名 包信息保存在package.json的dependencies中 * 开发依赖 npm i -D 包名 -D 等效与 --save-dev npm i --save-dev 包名 包信息保存在package.json的devDependencies中 * 其他补充: * 全局依赖 npm i -g 包名 -g 等效与 --global npm i --global 包名 全局安装的包,可以在命令行中直接使用 * 安装所有依赖 npm i npm i --production 只安装dependencies中的依赖 * 卸载依赖 npm uninstall 包名 * 更新依赖 npm update 包名 * 查看依赖 npm list * 查看全局依赖 npm list -g * 查看依赖的版本 npm list 包名 * 查看全局依赖的版本 npm list -g 包名 * 查看包的详细信息 npm info 包名 * 查看包的更新日志 npm view 包名 versions * 查看全局安装目录位置 npm root -g * nodemon 可以监听js文件的变化,当文件发生变化时,自动重启项目 * 全局安装 npm i -g nodemon * 全局包使用 nodemon app.js * 全局卸载 npm uninstall -g nodemon 或者 npm r -g nodemon **/ 5.修改windows的执行策略
- js
/** * windows 默认不允许 npm 全局命令执行脚本文件,所以需要修改执行策略 * 第一种方式: * 以管理员身份打开powershell,输入以下命令 * set-ExecutionPolicy RemoteSigned * 选择A,表示同意 * 修改完成后,就可以执行 npm 全局命令了 * 第二种方式: * 在切换cmd命令行执行脚本 * **/ 6.环境变量 Path
- js
/** * 环境变量 Path 是一个系统变量,用于存储系统可执行文件的路径 * 当我们在命令行中输入一个命令时,系统会在 Path 中查找对应的可执行文件 * 如果找到了,就会执行该文件,否则就会报错 * 我们可以通过修改 Path 来添加我们自己的可执行文件 * 在命令行中输入以下命令 * setx /M Path "%Path%;C:\Users\用户名\AppData\Roaming\npm" * 其中,C:\Users\用户名\AppData\Roaming\npm 是 npm 全局安装的路径 * 修改完成后,就可以在命令行中执行 npm 全局命令了 * 补充:应用程序的可执行文件后缀(.exe / .cmd) **/ 7.npm 安装包的所有依赖
- js
/** * 安装包依赖 * 在项目协作中有一个常用命令就是npm i ,通过该命令可以依据 package.json 和 package-lock.json 文件安装所有依赖 * npm i 或者 npm install 会自动安装 package.json 和 package-lock.json 文件中的所有依赖 * node_modules 文件夹大多数情况下都不会存入版本库 **/ 8.npm 安装包的指定版本
- js
/** * 安装包的指定版本 * 在安装包时,可以通过@指定版本号 * npm i express@4.17.1 * 这样就可以安装指定版本的包了 **/ 9.npm 配置命令别名
- js
/** * 在package.json 文件中,可以通过 scripts 字段来配置命令别名 * 例如: * "scripts": { "start": "node app.js", "test": "echo \"Error: no test specified\" && exit 1" } * 这样就可以通过 npm run start 来执行 node app.js 命令了 * 如果想要配置全局命令别名,可以在 package.json 文件中添加 bin 字段 * 例如: * "bin": { "myapp": "app.js" } * 这样就可以通过 npm run myapp 来执行 node app.js 命令了 * start 可以直接使用npm start 来执行 其他的必须使用 run * npm run 有自动向上级目录查找的特性,跟require函数一样, * 对于陌生的项目,我们可以通过查看scripts属性来参考项目的一些操作 **/ 10.cnpm
- js
/** * 1.cnpm 介绍 * cnpm 是淘宝构建的npmjs.com的完全镜像,也称【淘宝镜像】,网站 https://npmmirror.com/ * cnpm 服务器部署在国内阿里云服务器上,可以提高包的下载速度 * 官方也提供了一个全局工具包 cnpm ,操作命令与npm 大体相同 * 2.安装 cnpm * 通过npm来安装cnpm工具 * npm install -g cnpm --registry=https://registry.npmmirror.com * -g 表示全局安装 * --registry=https://registry.npmmirror.com 表示指定镜像源 * 3.操作命令 * 功能 命令 * 初始化 cnpm init * 安装依赖 cnpm install 或者 cnpm i * 安装包 cnpm install 包名 或者 cnpm i 包名 cnpm i -S 包名 cnpm i -D 包名 cnpm i -g 包名 * 卸载包 cnpm uninstall 包名 或者 cnpm un 包名 或者 cnpm r 包名 **/ 11.配置淘宝镜像
- js
/** * 1.配置淘宝镜像 * npm config set registry https://registry.npmmirror.com * npm config get registry 查看镜像源 * npm config list 查看所有配置 * npm config delete registry 删除镜像源 * npm config edit 编辑配置文件 * 推荐使用nrm来管理镜像源 **/ 12.yarn
- js
/** * 1.安装yarn * npm install -g yarn * 2.操作命令 * 功能 命令 * 初始化 yarn init * 安装依赖 yarn 或者 yarn add * 安装包 yarn add 包名 或者 yarn add 包名 --save yarn add 包名 --dev yarn add 包名 --global * 卸载包 yarn remove 包名 或者 yarn rm 包名 * 更新包 yarn upgrade 包名 或者 yarn upgrade 包名 --latest * 清空缓存 yarn cache clean * 查看全局安装的包 yarn global list * 3.配置淘宝镜像 * yarn config set registry https://registry.npmmirror.com * 推荐使用yrm来管理镜像源 * 包管理工具不要混着用 ,切记! **/ 13.npm 发布包
- js
/** * 1.创建与发布 * 我们可以将自己开发的工具包发布到npm服务上,方便自己和其他开发者使用,操作如下: * 1.创建文件,并创建文件index.js,在文件中声明函数,使用module.exports导出 * 2.在命令行中执行npm init -y,生成package.json文件,填写包的信息(包的名字是唯一的 ,带有测试字眼会被垃圾回收机制回收) * 3.注册账号:https://www.npmjs.com/signup * 4.激活账号:(一定要激活) * 5.修改为官方的官方镜像(命令行中运行 nrm use npm) * 6.登录npm账号:npm login (输入账号,密码,邮箱) * 7.发布:npm publish 提交包 * 2.更新包 * 后续可以对自己发布的包进行更新,操作如下: * 1.更新包中的代码 * 2.测试代码是否可用 * 3.修改package.json中的版本号 * 4.运行npm publish发布包 * 3.删除包 * 如果发布的包有错误,或者不再使用,可以删除包,操作如下: * 1.运行npm unpublish 包名 --force * 注意: * 删除包需要满足一定的条件:https://docs.npmjs.com/cli/v6/commands/npm-unpublish * 1.你是发布包的作者 * 2.发布小于24小时 * 3.大于24小时后,没有其他包依赖,并且每周小于300下载量,并且只有一个维护者 * **/ 14.包管理工具扩展介绍
- js
/** * 扩展内容 * 在很多语言中都有包管理工具,比如: * 语言 包管理工具 * Java Maven、Gradle * Python pip * C# NuGet * 前端 npm、yarn、pnpm/other * PHP Composer * Go go mod * Rust cargo * Ruby rubygems * * 除了编程语言领域有包管理工具之外,操作系统层面也存在包管理工具,不过这个包指的是【软件包】 * 操作系统 包管理工具 网站 * Linux apt https://packages.ubuntu.com/ * Linux yum https://centos.pkgs.org/ * Windows Chocolatey https://chocolatey.org/packages * macOS Homebrew https://brew.sh/ * Centos yum https://packages.debian.org/stable/ * Ubuntu apt https://packages.ubuntu.com/ **/ 7.express框架
1. express介绍
- js
/** * express介绍(用于开发服务端应用) * express 是一个基于 Node.js 平台的 web 应用开发框架,提供一系列强大的特性帮助你创建各种 Web 和 Mobile 应用。 * 官方网址: https://www.expressjs.com.cn/ * 简单地说:express 是一个封装好的工具包,封装很多功能,便于我们开发WEB应用(HTTP服务器) * express 是一个轻量级的web框架,提供了很多便捷的功能,比如路由、中间件、模板引擎等 **/ 2. express安装
- js
/** * express安装 * 1.安装express * npm install express * 2.创建express应用 **/ // 导入express 模块 const express = require('express') // 创建express应用 const app = express() // 创建路由 app.get('/', (req, res) => { res.send('Hello World!') }) // 启动express应用 app.listen(3000, () => { console.log('Example app listening on port 3000!') }) 3. express路由
- js
/** * express路由 * 1.路由:指的就是映射关系,客户端请求的地址和服务器端处理请求的函数之间的映射关系 * 2.路由的组成:请求方法、路径、回调函数 组成 * 3.express中提供了一系列方法,可以很方便的使用路由,使用格式如下: * app.method(path, callback) * 4.代码示例: **/ // 导入express 模块 const express = require('express') // 创建express应用 const app = express() // 创建get路由 app.get('/', (req, res) => { res.send('Hello World!') }) // 创建post路由 app.post('/', (req, res) => { res.send('Hello World!') }) // 创建put路由 app.put('/', (req, res) => { res.send('Hello World!') }) // 创建delete路由 app.delete('/', (req, res) => { res.send('Hello World!') }) // 创建方法随意路由 app.all('/', (req, res) => { res.send('Hello World!') }) // 创建通配符路由(404) app.all('*', (req, res) => { res.send('Hello World!') }) // 启动express应用 app.listen(3000, () => { console.log('Example app listening on port 3000!') }) 4. express获取请求报文参数
- js
/** * express框架封装了一些API来方便获取请求报文中的数据,并且兼容原生HTTP模块的获取方法 **/ // 导入express 模块 const express = require('express') // 创建express应用 const app = express() // 创建get路由 app.get('/', (req, res) => { // 原生操作 // 1.获取请求报文中的URL参数 console.log(req.query) // 2.获取请求报文中的路径参数 console.log(req.params) // 3.获取请求报文中的请求体参数 console.log(req.body) // 4.获取请求报文中的请求头参数 console.log(req.headers) // 5.获取请求报文中的cookie参数 console.log(req.cookies) // 6.获取请求报文中的session参数 console.log(req.session) // 7.获取请求报文中的文件 console.log(req.file) // express操作(避免了解析) // 1.获取请求报文中的URL参数 console.log(req.path) // 2.获取请求报文中的路径参数 console.log(req.params) // 3.获取请求头 console.log(req.get('host')); }) // 启动express应用 app.listen(3000, () => { console.log('Example app listening on port 3000!') }) 5. express获取路由参数
- js
/** * 路由参数是指 URL 路径中的参数(数据) * 例如:/user/:id,其中 :id 就是路由参数 * 路由参数的获取通过 req.params 对象 **/ // 导入express 模块 const express = require('express') // 创建express应用 const app = express() // 创建get路由 app.get('/user/:id', (req, res) => { // 获取路由参数 console.log(req.params) }) // 启动express应用 app.listen(3000, () => { console.log('Example app listening on port 3000!') }) 6. express响应设置
- js
/** * express 框架封装了一些API来方便给客户端响应数据,并且兼容原生HTTP模块的获取方式 **/ // 导入express 模块 const express = require('express') // 创建express应用 const app = express() // 创建get路由 app.get('/user', (req, res) => { // express 中设置响应的方式兼容HTTP模块方式 res.statusCode = 200 res.setHeader('Content-Type', 'text/html; charset=utf-8') res.write('hello express') res.end() // express 中设置响应的方式 // 1.设置响应状态码 // res.status(200) // 2.设置响应头 // res.set('Content-Type', 'text/html; charset=utf-8') // 3.设置响应体 // res.send('hello express') // 含有中文会自动设置 Content-Type: text/html; charset=utf-8 响应头避免乱码 // 连贯操作 // res.status(200).set('Content-Type', 'text/html; charset=utf-8').send('hello express') // 其他响应 // res.redirect('https://www.baidu.com') // 重定向 // res.json({ name: '张三', age: 18 }) // 返回json数据 // res.sendFile(__dirname + '/index.html') // 返回文件内容 // res.download(__dirname + '/index.html') // 下载文件 }) // 启动express应用 app.listen(3000, () => { console.log('Example app listening on port 3000!') }) 7. express中间件
- js
/** * 1. 什么是中间件 * 中间件(Middleware)本质就是一个回调函数 * 中间件函数可以像路由回调一样访问请求对象(request)、响应对象(response)和应用程序的请求-响应循环中的下一个中间件函数 * 2. 中间件的作用 * 中间件的作用就是使用函数封装公共操作,简化代码 * 3. 中间件的分类 * 1. 全局中间件 * 2. 路由中间件 * 4. 定义全局中间件 * 每一个请求到达服务端之后都会执行全局中间件函数 * 声明中间件函数 **/ // 1.全局中间件 let middleware = (req, res, next) => { // 实现功能代码 // ... // 调用next函数将控制权交给下一个中间件函数 // 执行next函数 (当如果希望执行完中间件函数之后,仍然继续执行路由中的回调函数,必须调用next) next() } // 注册全局中间件 app.use(middleware) // 2. 路由中间件 let checkCodeMiddleware = (req, res, next) => { // 实现功能代码 // ... // 调用next函数将控制权交给下一个中间件函数 // 执行next函数 (当如果希望执行完中间件函数之后,仍然继续执行路由中的回调函数,必须调用next) next() } // 注册路由中间件(哪个路由需要使用添加哪个路由中间件) app.get('/checkCode', checkCodeMiddleware, (req, res) => { // ... }) // 3. 静态资源中间件设置 // 访问静态资源时 中间件会根据访问资源类型自动封装响应头类型 app.use(express.static(__dirname+'/public')) // 注意事项: // 1. index.html文件为默认打开的资源 // 2. 如果静态资源与路由规则同时匹配,谁先匹配谁就响应 // 3. 路由响应动态资源,静态资源中间件响应静态资源 8. express获取请求体数据
- js
// 获取请求体数据 body-parser中间件 // 1. 安装body-parser中间件 // npm install body-parser // 2. 引入body-parser中间件 const bodyParser = require('body-parser') // 3.获取中间件函数 // 处理querystring 类型数据 const querystringParser = bodyParser.urlencoded({ extended: false }) // 处理json 类型数据 const jsonParser = bodyParser.json() // 4.设置路由中间件,然后使用 request.body 获取请求体数据 app.post('/login', querystringParser, (req, res) => { // 获取请求体数据 const { username, password } = req.body // ... }) 9. 防盗链
- js
// 1.导入 express 模块 const express = require('express') // 2.创建 express 应用对象 const app = express() // 3.声明全局中间件拦截 app.use((req, res, next) => { // 1. 获取请求头中的 referer const referer = req.get('referer') // 2. 判断 referer 是否为空 if (referer) { // 3. 获取 referer 的域名部分 const host = new URL(referer).host // 4. 判断 host 是否为当前网站 if (host !== 'localhost:3000') { // 5. 返回 403 禁止访问 res.status(403).send('禁止访问') return } next() } }) // 3.设置路由中间件拦截 app.use('/public', (req, res, next) => { // 1. 获取请求头中的 referer const referer = req.get('referer') // 2. 判断 referer 是否为空 if (referer) { // 3. 获取 referer 的域名部分 const host = new URL(referer).host // 4. 判断域名是否为当前域名 if (host === 'localhost:3000') { // 5. 如果是当前域名,则继续处理请求 next() } else { // 6. 如果不是当前域名,则返回 res.send('非法盗链') } } }) 10. 路由模块化
- js
// 1.创建一个模块文件夹(routes) // 2.在模块文件夹中分别创建不同模块的 js文件(如:user.js) // 3.在 user.js 中定义路由 const express = require('express') const router = express.Router() router.get('/login', (req, res) => { res.send('登录页面') }) router.get('/register', (req, res) => { res.send('注册页面') }) module.exports = router // 4.在主模块app.js 中引入路由模块 const express = require('express') const app = express() const userRouter = require('./routes/user') // 如果设置路由前缀 // app.use('/api', 导入的模块路由) // app.use('/api', userRouter) app.use(userRouter) app.listen(3000, () => { console.log('服务器已启动') }) // 11. EJS模板引擎
- js
/** * 1. 什么是模板引擎 * 模板引擎是分离用户界面和业务数据的一种技术 * 通过模板引擎,可以将数据动态的渲染到用户界面上 * 模板引擎有很多种,如:art-template、ejs、pug等 * 这里我们使用ejs模板引擎 * 2. 什么是ejs * ejs是一个基于Node.js的模板引擎,它可以将数据动态的渲染到HTML页面中 * 官网: https://ejs.co/ * 中文网站: https://ejs.bootcss.com/ * 3. 如何使用ejs * 1. 安装ejs * npm install ejs --save **/ // 示例代码: // 1.引入ejs const ejs = require('ejs') // 2.定义数据 const str = 'hello world' const data = ['张三', '李四', '王五'] let isLogin = true // 3.ejs解析模板返回结构 // <%= %> 是ejs解析内容的标记,作用是输出当前表达式的执行结构 // 1.变量渲染 // const str = ejs.render('<%= str %>', {str: str}) // 2.数组渲染 const str = ejs.render(`<ul> <% data.forEach(item=>{ %> <li><%= item %></li> <% }) %> </ul>`, {data: data}) // 3.条件渲染 const str = ejs.render(`<% if(isLogin){ %> <p>欢迎回来</p> <% }else{ %> <p>请先登录</p> <% } %>`, {isLogin: isLogin}) 12.Express 中使用ejs
- js
// 导入 express 模块 const express = require('express') // 导入 ejs 模块 const ejs = require('ejs') // 导入 path 模块 const path = require('path') // 创建 express 的服务器实例 const app = express() // 告诉 express 服务器,使用 ejs 作为模板引擎 app.set('view engine', 'ejs') // pug twing // 设置模板文件存放位置 模板文件:具有模板语法内容的文件 app.set('views',path.resolve(__dirname + './views')) // 定义路由 app.get('/', (req, res) => { // 渲染 EJS 模板,并渲染到浏览器中 // res.render(模板的文件名, 数据) // 例如: let str = 'hello world' res.render('home', {str: str}) // 在views 目录中创建 home.ejs 文件 不然找不到这个文件 }) // 启动服务器 app.listen(3000, () => { console.log('Express server running at http://127.0.0.1:3000') }) 13.express-generator工具
- js
// 作用:通过应用生成工具 express-generator 来快速创建一个 express 应用骨架 // 1.安装express-generator // npm install express-generator -g // 2.创建express应用 // express -e myapp // -e 表示使用 ejs 模板 // 也可以使用 npx express myapp // 3.安装依赖 // cd myapp && npm install // 4.启动应用 // npm start // 5.访问应用 // localhost:3000 // 6.需要热部署配置 // {"scripts": { // "start": "node ./bin/www" 中 node 修改为nodemon // "dev": "nodemon ./bin/www" 或者添加启动项 // } // } // 7.添加模块或者修改自定义内容可自行处理 14.express 文件上传报文
- js
// 1.创建文件上传ejs文件模板(form表单 enctype="multipart/form-data") // 2.下载文件处理工具包(formidable) // npm install formidable --save // 3.引入formidable const {formidable}= require("formidable"); // 4.使用formidable处理文件上传 router.post('/portrait', function(req, res, next) { // 创建formidable实例 const form = formidable({ multiples: true, //设置上传文件的保存目录 uploadDir:__dirname + "/../public/uploads", //保留文件扩展名 keepExtensions: true }); // 解析请求 form.parse(req, (err, fields, files) => { if (err) { next(err); return; } // 服务器保存该图片访问的url地址 保存在数据库中 let url = "/uploads/" + files.portait[0].newFilename; res.send(url); }); }); 15.lowdb
- js
// 1.安装lowdb 且为每条json数据添加唯一id // npm install lowdb // npm install shortid // // 2.使用lowdb(创建lowdb文件 封装如下操作) const low = require('lowdb') const shortid = require('shortid') // 3.引入FileSync模块 const FileSync = require('lowdb/adapters/FileSync') const adapter = new FileSync(__dirname + '/../data/db.json') // 获取db对象 const db = low(adapter) // 创建id let id = shortid.generate(); // 初始化数据 db.defaults({ posts: [], user: {} }).write() // 添加数据 db.get('posts').push({ id: id, title: 'lowdb' }).write() // 插入数据 db.get('posts').unshift({ id: id, title: 'lowdb0' }).write() // 获取所有posts数据 db.get('posts').value() // 获取id为1的数据 db.get('posts').find({ id: 1 }).value() // 获取id为1的数据的title db.get('posts').find({ id: 1 }).get('title').value() // 更新id为1的数据的title db.get('posts').find({ id: 1 }).assign({ title: 'lowdb1' }).write() // 删除id为1的数据 db.get('posts').remove({ id: 1 }).write() // 删除所有posts数据 db.get('posts').remove().write() 8.MongoDB
1.MongoDB简介
- js
/** * 1.什么是MongoDB * MongoDB是一个基于分布式文件存储的数据库,官方网址: https://www.mongodb.com/ * MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。 * 2.数据库是什么 * 数据库(Database)是按照数据结构来组织、存储和管理数据的应用程序。 * 3.数据库的作用 * 数据库的主要作用就是 管理数据,对数据进行 增(c)、删 (d)、改(u)、查(r)操作。 * 4.数据库管理数据的特点 * 相比于纯文件管理数据,数据库管理数据有如下特点: * 1.速度更快 * 2.扩展性更强 * 3.安全性更高 * 4.数据持久化 * 5.数据结构化 * 6.数据一致性 * 5.为什么选择MongoDB * 1.易用性:MongoDB 是一个面向文档存储的数据库,操作起来比较简单和容易。 * 2.灵活性:MongoDB 非常灵活,它不需要像关系型数据库那样预先定义和设置表结构。 * 3.可扩展性:MongoDB 是一个分布式数据库,可以很容易地扩展到多台服务器。 * 4.高性能:MongoDB 是一个高性能的数据库,读写速度非常快。 * 5.高可用性:MongoDB 支持自动复制和故障转移,可以保证数据的可靠性和可用性。 * 6.语法相似:操作语法与JavaScript语法相似,容易上手,学习成本低。 * 6.应用场景 * 1.内容管理系统、博客和 论坛,如WordPress、Joomla、Drupal等。 * 2.实时应用,如实时分析、实时搜索、实时广告等。 * 3.移动应用,如移动应用的后端存储。 * 4.游戏,如游戏数据存储。 * 5.物联网,如物联网设备的数据存储。 * 6.大数据,如大数据分析。 * 7.电子商务,如电商网站的商品信息、订单信息等。 **/ 2.MongoDB核心概念
- js
/** * 1.数据库(database) * 数据库是一个物理容器,用于存储一个或多个集合。一个数据库通常包含一个或多个集合,每个集合包含一个或多个文档。 * 2.集合(collection) * 集合是一组文档,类似于关系型数据库中的表。集合中的文档可以具有不同的结构,类似于关系型数据库中的行 * 3.文档(document) * 文档是MongoDB中的基本数据结构,类似于关系型数据库中的行。文档由键值对组成,类似于JSON对象。 * 4.字段(field) * 字段是文档中的键值对,类似于关系型数据库中的列。字段名是字符串,字段值可以是任何类型的数据。 * 5.索引(index) * 索引是用于加速查询操作的数据结构。MongoDB 支持多种类型的索引,如单字段索引、复合索引、全文索引等。 * 6.查询(query) * 查询是用于从集合中检索文档的操作。查询可以指定查询条件、排序方式、投影等。 * 7.更新(update) * 更新是用于修改集合中的文档的操作。更新操作可以修改文档中的字段值、添加或删除字段等。 * 8.删除(delete) * 删除是用于从集合中删除文档的操作。删除操作可以指定删除条件。 * 9.聚合(aggregation) * 聚合是用于对集合中的文档进行分组和计算的操作。聚合操作可以指定聚合管道,如分组、过滤、排序、计算等。 * 10.事务(transaction) * 事务是用于保证一组操作要么全部成功,要么全部失败的操作。MongoDB 4.0及以上版本支持多文档事务。 * 11.复制(replication) * 复制是用于将数据从一个节点复制到另一个节点的操作。MongoDB 支持自动复制和手动复制。 * 12.分片(sharding) * 分片是用于将数据分布在多个节点上的操作。MongoDB 支持自动分片和手动分片。 * 13.备份(backup) * 备份是用于将数据从一个节点复制到另一个节点的操作。MongoDB 支持自动备份和手动备份。 * 14.恢复(restore) * 恢复是用于将数据从一个节点复制到另一个节点的操作。MongoDB 支持自动恢复和手动恢复。 * 15.监控(monitoring) * 监控是用于监视MongoDB性能和状态的操作。MongoDB 提供了多种监控工具,如mongostat、mongotop、mongoreplay等。 * 16.安全性(security) * 安全性是用于保护MongoDB数据免受未授权访问的操作。MongoDB 提供了多种安全性功能,如身份验证、授权、加密等。 * 可以通过JSON文件来理解MongoDB中的数据结构。例如,以下是一个包含用户信息的JSON文件: * { * "_id": ObjectId("5f9a3c8e4f9a3c8e4f9a3c8e"), * "name": "John Doe", * "age": 30, * "email": "john.doe@example.com", * "address": { * "street": "123 Main St", * "city": "Anytown", * "state": "CA", * "zip": "12345" * }, * "list": [ * { "item": "apple", "quantity": 2 }, * ] * } * 这个JSON文件就好比是一个数据库,一个MongoDB服务下可以有N个数据库,每个数据库下可以有N个集合,每个集合下可以有N个文档。 * JSON文件中的一级属性的数组值好比一个集合, * 数组中的对象好比是文档, * 对象中的属性和值好比是文档中的字段和值。 * 一般情况下: * 1.一个项目使用一个数据库, * 2.一个集合会存储同一种类型的数据 **/ 3.MongoDB的安装与启动
- js
/** * 1.安装MongoDB: * 1.下载地址: /https://www.mongodb.com/try/download/community * 2.建议选择zip类型,通用性更强 * 3.配置步骤如下: * 1.将压缩包移动到自己选择的位置进行解压 * 2.在解压后的文件夹中创建data文件夹,mongodb会将数据默认保存在这个文件夹(自定义位置 启动的时候使用命令 mongod --dbpath 指定data) * 3.以mongodb中bin目录作为工作目录,启动命令行 * 4.在命令行中输入mongod启动mongod服务(命令行指的是mongod文件夹bin目录下的命令行) * 2.使用MongoDB: * 1.在命令行中输入mongo启动mongo客户端(命令行指的是mongod文件夹bin目录下的命令行) **/ 4.常用命令
- js
/** * 数据库命令 * 1.查看当前数据库 * 1.命令:db * 2.显示所有数据库 * 1.命令:show dbs * 3.切换数据库 * 1.命令:use 数据库名 * 4.删除数据库 * 1.命令:db.dropDatabase() **/ /** * 集合命令 * 1.创建集合 * 1.命令:db.createCollection('集合名') * 2.查看当前数据库中所有的集合 * 1.命令:show collections * 3.查看集合中的所有文档 * 1.命令:db.集合名.find() * 4.重命名集合 * 1.命令:db.集合名.renameCollection("新集合名") * 5.删除集合 * 1.命令:db.集合名.drop() **/ /** * 文档命令 * 1.插入文档 * 1.命令:db.集合名.insert(文档对象) 例如: db.user.insert({name:"张三",age:18}) * 2.更新文档 * 1.命令:db.集合名.update({查询条件},{更新内容}) 例如: db.user.update({name:"张三"},{$set:{age:20},$push:{sex:"男"}}) * 3.删除文档 * 1.命令:db.集合名.remove({查询条件}) 例如: db.user.remove({name:"张三"}) * 4.查询文档 * 1.命令:db.集合名.find({查询条件}) 例如: db.user.find({name:"张三"}) * 5.查询所有文档 * 1.命令:db.集合名.find() 例如: db.user.find() * 6.查询指定数量的文档 * 1.命令:db.集合名.find().limit(数量) 例如: db.user.find().limit(2) * 7.跳过指定数量的文档 * 1.命令:db.集合名.find().skip(数量) 例如: db.user.find().skip(2) * 8.排序查询 * 1.命令:db.集合名.find().sort({字段名:1}) 例如: db.user.find().sort({age:1}) * 9.查询指定字段 * 1.命令:db.集合名.find({查询条件},{字段名:1}) 例如: db.user.find({name:"张三"},{name:1,age:1}) * 10.查询不等于 * 1.命令:db.集合名.find({字段名:{$ne:值}}) 例如: db.user.find({age:{$ne:18}}) * 11.查询大于 * 1.命令:db.集合名.find({字段名:{$gt:值}}) 例如: db.user.find({age:{$gt:18}}) * 12.查询小于 * 1.命令:db.集合名.find({字段名:{$lt:值}}) 例如: db.user.find({age:{$lt:18}}) * 13.查询大于等于 * 1.命令:db.集合名.find({字段名:{$gte:值}}) 例如: db.user.find({age:{$gte:18}}) * 14.查询小于等于 * 1.命令:db.集合名.find({字段名:{$lte:值}}) 例如: db.user.find({age:{$lte:18}}) * 15.查询包含 * 1.命令:db.集合名.find({字段名:{$in:[值1,值2]}}) 例如: db.user.find({name:{$in:["张三","李四"]}}) * 16.查询不包含 * 1.命令:db.集合名.find({字段名:{$nin:[值1,值2]}}) 例如: db.user.find({name:{$nin:["张三","李四"]}}) * 17.查询空值 * 1.命令:db.集合名.find({字段名:{$in:[null]}}) 例如: db.user.find({name:{$in:[null]}}) **/ 9.Mongoose
1.介绍及安装使用
- js
/** * 1.介绍 * Mongoose 是一个对象文档模型库,官网 : https://mongoosejs.com/ 或 https://mongoosejs.net/ * 2.作用 * 方便使用代码操作 MongoDB 数据库 * 3.使用流程: * 1.安装 mongoose * npm i mongoose * 2.引入 mongoose * const mongoose = require('mongoose') // 设置 striceQuery 为 true // 此时 mongoose 会以严格模式运行,即在没有使用 schema 定义的字段,将无法保存到数据库 mongoose.set('strictQuery', true) * 3.连接数据库 * mongoose.connect('mongodb://localhost:27017/test', {useNewUrlParser: true, useUnifiedTopology: true}) * 4.设置连接回调 * 连接成功 (官方推荐使用once,不推荐使用on ,只连接一次) * mongoose.connection.once('open', () => { * console.log('连接成功') * // 5.创建文档结构对象(设置集合中文档的属性以及属性值类型) * const UserSchema = new mongoose.Schema({ * name: String, * age: Number, * email: String, * password: String, * status: { * type: Number, * default: 1 * } * }) * // 6.创建文档模型对象 (对文档操作的封装对象) * const UserModel = mongoose.model('User', UserSchema) * // 7.新增 * UserModel.create({ * name: '张三', * age: 20, * email: '123@qq.com', * password: '123456', * status: 1 * }, (err, doc) => { * 判断是否有错误 * if (err) { * console.log(err) * return; * } * console.log(doc) * 关闭数据库连接 (项目运行过程中,不会添加改代码) * mongoose.disconnect() * }) * }) * 连接失败 * mongoose.connection.on('error', () => { * console.log('连接失败') * }) * 连接关闭 * mongoose.connection.on('close', () => { * console.log('连接关闭') * }) **/ 2.字段类型
- js
/** * 文档结构可以选的常用字段类型列表 * 类型 描述 * String 字符串 * Number 数字 * Date 日期 * Buffer 二进制(Buffer 对象) * Boolean 布尔值 * Mixed 任意类型,需要使用 mongoose.Schema.Types.Mixed指定 * ObjectId 对象ID,需要使用 mongoose.Schema.Types.ObjectId指定 * Decimal128 高精度数字,需要使用 mongoose.Schema.Types.Decimal128指定 * Array 数组,也可以使用[]来标识,指定一个数组,数组中的每个值都必须是给定类型 **/ 3.字段验证
- js
/** * 1. required: true 必填项 * 2. default: 默认值 * 3. enum: ['A', 'B', 'C'] 枚举值 * 4. maxlength: 10 最大长度 * 5. minlength: 5 最小长度 * 6. max: * 7. min: * 8. match: /正则表达式/ 正则表达式 * 9. validate: function(value) { return value.length > 5 } 自定义验证函数 * 10. trim: true 去除字符串两端的空格 * 11. lowercase: true 将字符串转换为小写 * 12. uppercase: true 将字符串转换为大写 * 13. unique: true 唯一值 * 14. sparse: true 稀疏索引 * 15. select: false 不查询该字段 * 16. ref: 'Model' 引用其他模型 * 17. enum: ['A', 'B', 'C'] 枚举值必须是传递的这几个值不然报错 **/ // 使用案例: const mongoose = require('mongoose'); const Schema = mongoose.Schema; const UserSchema = new Schema({ name: { type: String, required: true }, age: { type: Number, min: 18, max: 60 }, email: { type: String, unique: true, match: /.+@.+\..+/ }, password: { type: String, required: true, select: false }, role: { type: String, enum: ['admin', 'user'] }, createdAt: { type: Date, default: Date.now }, updatedAt: { type: Date, default: Date.now }, }); const User = mongoose.model('User', UserSchema); 4.操作文档
- js
// 删除文档 const mongoose = require('mongoose'); mongoose.connect('mongodb://localhost/users', { useNewUrlParser: true, useUnifiedTopology: true }); mongoose.connection.once('open', () => { // 创建文档结构对象 // 设置集合中文档的属性以及属性值类型 const userSchema = mongoose.Schema({ name: String, age: Number, }); // 创建模型对象 对文档操作的封装对象 mongoose 会使用集合名称的复数,创建集合(User => 生成文档名称 Users) const User = mongoose.model('User', userSchema) // 删除一条数据 User.deleteOne({ name: '张三' }, (err,data) => { if (err) { console.log('删除失败',err); return; } // 删除成功 输出 删除的数据 console.log(data); }) // 批量删除数据 User.deleteMany({ age: { $gt: 20 } }, (err,data) => { if (err) { console.log('删除失败',err); return; } // 删除成功 输出 删除的数据 console.log(data); }) // 更新文档 更新一条 User.updateOne({ name: '张三' }, { age: 18 }, (err,data) => { if (err) { console.log('更新失败',err); return; } // 更新成功 输出 更新的数据 console.log(data); }) // 更新文档 更新多条 User.updateMany({ age: { $gt: 20 } }, { age: 18 }, (err,data) => { if (err) { console.log('更新失败',err); return; } // 更新成功 输出 更新的数据 console.log(data); }) // 查询文档 查询一条 User.findOne({ name: '张三' }, (err,data) => { if (err) { console.log('查询失败',err); return; } // 查询成功 输出 查询的数据 console.log(data); }) // 查询文档 查询多条 User.find({ age: { $gt: 20 } }, (err,data) => { if (err) { console.log('查询失败',err); return; } // 查询成功 输出 查询的数据 }) // 根据ID查询文档 User.findById('5f9b8e9c6f9b8e9c6f9b8e9c', (err,data) => { if (err) { console.log('查询失败',err); return; } // 查询成功 输出 查询的数据 console.log(data); }) // 查询所有文档 (查询参数项可省略) User.find({}, (err,data) => { if (err) { console.log('查询失败',err); return; } // 查询成功 输出 查询的数据 console.log(data); }) }) 5.条件控制
- js
/** * 符号 含义 $set: 修改 $inc: 递增 $unset: 删除 $push: 添加 $addToSet: 添加到集合中 $pop: 删除 $pull: 删除 $pullAll: 删除多个 $pushAll: 添加多个 $each: 遍历 $slice: 截取 $ne: 不等于 $gt: 大于 $gte: 大于等于 $lt: 小于 $lte: 小于等于 $in: 在集合中 $nin: 不在集合中 $or: 或 $nor: 逻辑非 $not: 不等于 $exists: 存在 $all: 全部 $elemMatch: 元素匹配 $size: 长度 $mod: 取模 $regex: 正则 $text: 文本搜索 $where: 条件 $geoNear: 地理位置搜索 $near: 地理位置搜索 $nearSphere: 地理位置搜索 $maxDistance: 最大距离 $minDistance: 最小距离 $geoWithin: 地理位置搜索 $box: 矩形 $center: 圆心 $centerSphere: 圆心 $polygon: 多边形 $uniqueDocs: 唯一文档 $bitsAllClear: 位运算 $bitsAllSet: 位运算 $bitsAnyClear: 位运算 $bitsAnySet: 位运算 $comment: 注释 $isolated: 隔离 $elemMatch: 元素匹配 $exists: 存在 $type: 类型 **/ // 案例: // 1.运算符 db.getCollection('user').find({age:{$gt:20}}) // 年龄大于20 // 2.逻辑或运算符 db.getCollection('user').find({$or:[{age:{$gt:20}},{age:{$lt:10}}]}) // 年龄大于20或者小于10 // 3.逻辑与运算符 db.getCollection('user').find({$and:[{age:{$gt:20}},{age:{$lt:30}}]}) // 年龄大于20并且小于30 // 4.正则匹配(条件中可以直接使用JS的正则语法,通过正则可以进行模糊查询) db.getCollection('user').find({name:/李/}) // 名字含有李的 db.getCollection('user').find({name:new RegExp('z')}) // 名字含有李的 6.个性化读取
- js
// 1.字段筛选 // 0:不要的字段 // 1:要的字段 db.getCollection('user').find().select({name:1,age:1,_id:0}).exec(function (err, docs) { if (err) throw err; console.log(docs); mongoose.connection.close() }) // 2.数据排序 // sort:排序,1:升序,-1:降序 db.getCollection('user').find().sort({age:1}).exec(function (err, docs) { if (err) throw err; console.log(docs); mongoose.connection.close() }) // 3.数据分页 // limit:限制条数 // skip:跳过条数 db.getCollection('user').find().skip(10).limit(10).exec(function (err, docs) { if (err) throw err; console.log(docs); mongoose.connection.close() }) // 4.数据统计 // count:统计条数 db.getCollection('user').count(function (err, count) { if (err) throw err; console.log(count); mongoose.connection.close() }) // 5.数据去重 // distinct:去重 db.getCollection('user').distinct('name',function (err, docs) { if (err) throw err; console.log(docs); mongoose.connection.close() }) 7.代码模块化
- js
// 创建一个config.js文件,用于存放数据库配置信息 module.exports = { DBNAME: 'users', DBHOST: 'localhost', DBPORT: '27017', } - js
/** * @description: 封装数据库操作 * @param {*} success 连接成功回调函数 * @param {*} error 连接失败回调函数 * @return {*} **/ // 提取公共代码块 db/db.js module.exports = function(success,error){ // 如果不传递失败的回调 设置一个默认值 if(typeof error !== 'function'){ error=()=>{ throw new Error('连接失败') } } // 1.引入模块 const mongoose = require('mongoose'); // 导入配置文件 const { DBNAME, DBHOST, DBPORT } = require('./config') // 设置 strictQuery 为 true mongoose.set('strictQuery', true); // 2.连接数据库 mongoose.connect(`mongodb://${DBHOST}:${DBPORT}/${DBNAME}`, { useNewUrlParser: true, useUnifiedTopology: true }); // 3.设置回调 // 设置连接成功回调 once 只执行一次 事件回调函数只执行一次 mongoose.connection.once('open', function () { success() }) // 4.设置连接失败回调 mongoose.connection.on('error', function () { error() }) // 5.设置关闭回调 mongoose.connection.on('close', function () {}) } - js
// 抽离 modules/user.js // 1.引入模块 const mongoose = require('mongoose') // 设置集合中文档的属性以及属性值类型 let UserSchema = new mongoose.Schema({ name: String, age: Number, email: String }) // 3.创建模型 let UserModel = mongoose.model('User', UserSchema) // 4.导出模型对象 module.exports = UserModel - js
// 使用封装模块 // 导入 common.js文件 const db = require('./db/db.js') // 导入 User 模型 const UserModel = require('./modules/user.js') // 1.调用函数 db(()=>{ UserModel.create({ name:'张三', age:18, email:'zhangsan@qq.com' },(err,doc)=>{ if(err) throw err; console.log(doc) }) console.log('连接成功') }) 9.图形化操作工具
- 我们可以使用图形化操作工具对MongoDB数据库进行操作,常用的图形化工具包括
- 1.Robo 3T 免费的, 下载地址
- 2.Navicat Premium 收费,功能强大, 下载地址